
type
status
slug
summary
tags
category
icon
password
new update day
Property
Oct 22, 2023 01:31 PM
created days
Last edited time
Oct 22, 2023 01:31 PM
0 需求描述
不知道各位有没有遇到和我相似的情况呢?有时候在查找一些书籍的 PDF 资料的时候,总是或多或少的遇到没有自带目录的 PDF 文件,对于一些章节多、体量大的 PDF 文件,在阅读的时候没有对应的目录进行快速导航的话,总是非常的不方便。
这不昨天在研究一些从未接触过的知识领域的时候,在找到相关书籍的 PDF 资料的时候,就发现自己能够找到的所有 PDF 资料都是没有目录存在的,于是就搜索了一下相关的解决方案。经过搜索发现大家对于这种需求的解决方案可以大致分为两种。
- 第一种解决方案:使用一些拥有编辑功能的专业 PDF 阅读器,比如
Adobe Acrobat DC、WPS office、福昕等,直接进行 PDF 页面编辑,添加一个单独的目录页面,手动编写目录页,最终保存下来。当然也可以将 PDF 转化成 Word 文件,在 word 里面修改完成后,自动生成目录页然后导出 PDF。 - 这种解决方案适合需要在文件里面添加目录页的需求,与我的需求不符,所以不考虑。同时也过于复杂需要手动操作,工作量太大不符合我的需求。
- 第二种解决方案:生成 PDF 阅读软件可识别的目录(类似于书签?不知道怎么准确描述,不过大家看图之后肯定能明白),从而实现对书籍章节的快速定位与查阅。
目录展示
1 自动化解决方案
经过搜索发现很多人都有类似的需求,同时也已经开发出了相应的自动化工具。pdf.tocgen 就是一个这方面的优秀工具,其项目地址如下:
1.1 简单的原理介绍
pdf.tocgen 是一个用于自动提取和生成 PDF 文件的目录 (ToC) 的命令行工具组。它使用嵌入式字体属性(比如所使用的字体、大小)和标题位置来推断 PDF 文件的基本轮廓。就如上面的工作流程所示的,输入 PDF 由
pdfxmeta 工具提取相关的目录信息,保存下来,然后通过管道传输给 pdftocgen 工具生成对应的目录文本文件(你可以查看编辑它),最终在你确定了目录的正确性之后可以使用 pdftocio 工具,将生成的目录嵌入到要修改的 PDF 文件中,最终生成带有目录结构的 out.pdf。注意:虽然这个工具组在设计时旨在与任何软件生成的 PDF 文件一起使用时都有效!但是通过上面的原理介绍,我们也能发现,这个工具无法在扫描版的 PDF 文件上使用,因为扫描版本的 PDF 上面只有图片没有相应的文字信息。
1.2 安装介绍
此工具组是使用
python3 开发的,如果想使用这个工具组的话,需要你拥有 python3.7 或者以上版本(官方推荐 python3.7 与 python3.9 版本)的环境。1.2.1 使用 pip 安装
- 全局安装
- 当前用户安装
1.2.2 使用 yay 安装
如果你是 Arch Linux 用户,那么你完全可以使用 yay 从 AUR 安装。
1.3 基本使用方法
在开始之前、我们再介绍一下各个工具在整个工作流中的作用
pdfxmeta:提取标题的元数据(字体属性、位置)以构建配置文件。
pdftocgen:根据配置文件中生成目录。
pdftocio:将目录导入PDF文档。
1.3.1 使用 pdfxmeta 抓取标题的元数据
- 其中
-p参数后面跟随你想要处理的 PDF 页码
- 其中
-a参数是你想要抓取的标题的级别(一级标题就是1)
- 其中
"Section"就是你想要抓取元数据的标题内容
- 其中
>>是输出重定向符号,将获取的标题原数据信息写入recipe.toml配置文件中去
原数据抓取示例
注意:如果你的 PDF 文件是扫描版,然后在上面进行文字识别做成的可复制文字的 PDF 文件,那么你可能需要手动检查相关的元数据抓取输出,将需要的元数据信息手动写入
recipe.toml 文件中去。就比如下面的示例:如果有多个匹配,则需要自己进行手动选择
注意:你可以随时像下面这样检查在应用自己的配置文件之后目录的生成效果。
- 临时应用配置查看目录生成效果
1.3.2 使用配置好的元数据生成目录
将配置传给
pdftocgen 工具即可生成目录1.3.3 将目录导入至 PDF 文件中
- 如果上面自动生成的目录没有错误那么你可以用下面的命令直接导入
- 如果你想在导入之前先编辑目录,可以参考下面的命令
1.4 高级使用技巧
这三个程序中的每一个都有一些额外的功能。使用
-h 选项查看您可以传入的所有选项。1.4.1 pdftocio
pdftociopdftocio 这个工具就能最好地证明这一点,这个工具自己本身就能做很多事情。- 将 PDF 中现有的目录显示到标准输出:
- 将 PDF 中的现有目录写入名为
toc的文件:
- 将
toc文件写回doc.pdf:
- 指定输出 PDF 的名称:
- 将目录从
doc1.pdf复制到doc2.pdf:
- 打印目录以供阅读:
1.4.2 pdftocgen
pdftocgen- 如果已经拥有了
doc.pdf的现有配置rcp.toml,那么可以应用它并将大纲打印到标准输出
- 将目录输出到名为 toc 的文件中:
- 将生成的目录导入到 PDF 文件中并输出到
doc_out.pdf文件:
- 打印生成的目录以供阅读:
- 如果要在页面中包含每个标题的垂直位置,请使用 -v 标志
pdftocio可以理解输出中的垂直位置,以生成链接到标题确切位置的目录条目,而不是页面顶部。
注意:这里
pdftocio 的默认输出是 doc_out.pdf。1.4.3 pdfxmeta
pdfxmeta- 在整个 PDF 中搜索
Anaphoric:
- 将使用自动设置的标题过滤器得到的结果输出
- 可以直接写入配置文件:
- 在整个 PDF 中以不区分大小写的方式搜索
Anaphoric:
- 使用正则表达式在整个 PDF 中进行不区分大小写的方式搜索
Anaphoric:
- 仅在第 203 页搜索:
- 转储第 203 页的整个页面:
- 转储整个 PDF 文档:
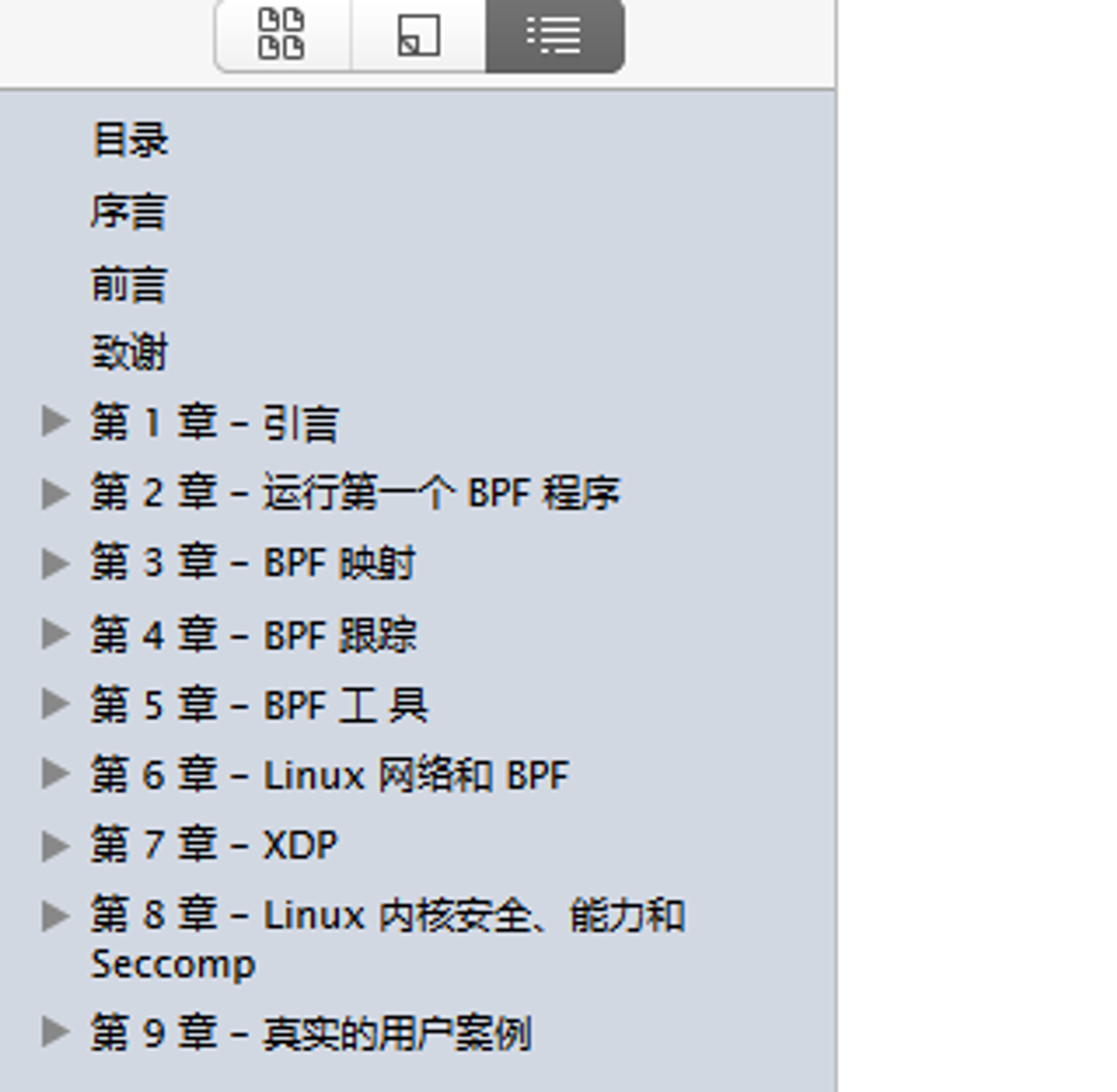
2 《Linux 内核观测技术BPF》目录配置分享
因为这个是扫描版后进行的文字识别、所以整理过程很麻烦,在这里分享一下
不带垂直位置的目录
带垂直位置的目录
- 作者:tangcuyu
- 链接:https://expoli.tech/articles/2022/12/12/tools-pdf.tocgen
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。
相关文章